
「Power Automate Desktop」キーワードでTwitter検索していたところ、チサさん( @chisa91010081 )のツイートから興味深い記事を見つけました。
現在
Power Automate Desktopで
プログラムを実験的に作っています。今、試してみたいのは
PDFで100ページほどの
書類の中から
あるキーワードが入っているページだけ
印刷する…そんなことができるのか??
https://note.com/chisa_pc_inst/n/nd81a4e5eba52 より
これは面白そうです!
さっそく作ってみることにしました。
PDFで指定したキーワードが含まれているページのみを印刷するフロー
フロー全体
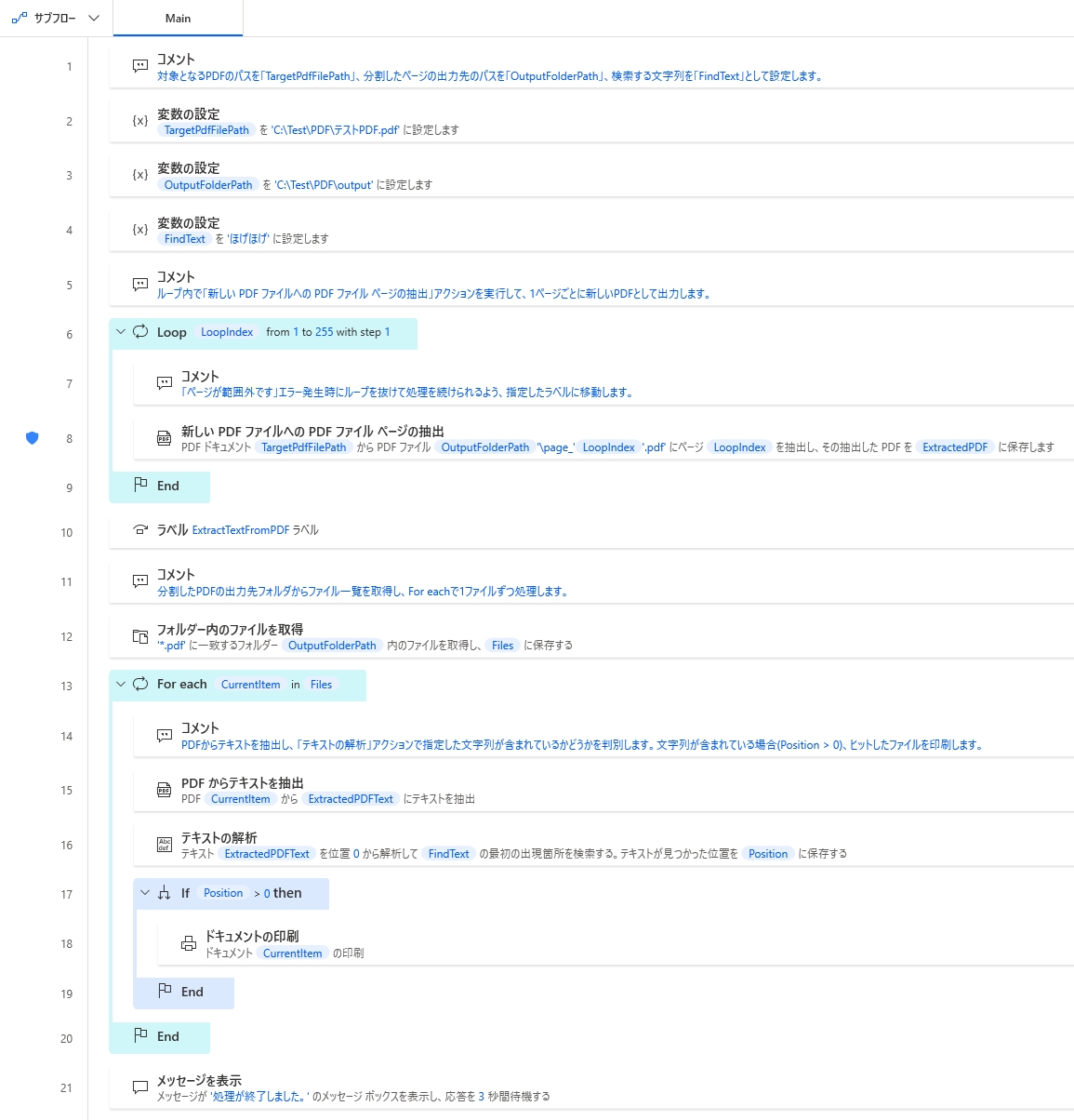
# 対象となるPDFのパスを「TargetPdfFilePath」、分割したページの出力先のパスを「OutputFolderPath」、検索する文字列を「FindText」として設定します。
SET TargetPdfFilePath TO $'''C:\\Test\\PDF\\テストPDF.pdf'''
SET OutputFolderPath TO $'''C:\\Test\\PDF\\output'''
SET FindText TO $'''ほげほげ'''
# ループ内で「新しい PDF ファイルへの PDF ファイル ページの抽出」アクションを実行して、1ページごとに新しいPDFとして出力します。
LOOP LoopIndex FROM 1 TO 255 STEP 1
# 「ページが範囲外です」エラー発生時にループを抜けて処理を続けられるよう、指定したラベルに移動します。
Pdf.ExtractPages PDFFile: TargetPdfFilePath PageSelection: LoopIndex ExtractedPDFPath: $'''%OutputFolderPath%\\page_%LoopIndex%.pdf''' IfFileExists: Pdf.IfFileExists.Overwrite ExtractedPDFFile=> ExtractedPDF
ON ERROR PageOutOfBoundsError
GOTO ExtractTextFromPDF
END
END
LABEL ExtractTextFromPDF
# 分割したPDFの出力先フォルダからファイル一覧を取得し、For eachで1ファイルずつ処理します。
Folder.GetFiles Folder: OutputFolderPath FileFilter: $'''*.pdf''' IncludeSubfolders: False FailOnAccessDenied: True SortBy1: Folder.SortBy.NoSort SortDescending1: False SortBy2: Folder.SortBy.NoSort SortDescending2: False SortBy3: Folder.SortBy.NoSort SortDescending3: False Files=> Files
LOOP FOREACH CurrentItem IN Files
# PDFからテキストを抽出し、「テキストの解析」アクションで指定した文字列が含まれているかどうかを判別します。文字列が含まれている場合(Position > 0)、ヒットしたファイルを印刷します。
Pdf.ExtractText PDFFile: CurrentItem ExtractedText=> ExtractedPDFText
Text.ParseForFirstOccurrence Text: ExtractedPDFText TextToFind: FindText StartingPosition: 0 IgnoreCase: True OccurrencePosition=> Position
IF Position > 0 THEN
System.PrintDocument DocumentPath: CurrentItem
END
END
Display.ShowMessageWithTimeout Message: $'''処理が終了しました。''' Icon: Display.Icon.Information Buttons: Display.Buttons.OK DefaultButton: Display.DefaultButton.Button1 IsTopMost: True Timeout: 3 ButtonPressed=> ButtonPressed
1. 変数の設定
対象となるPDFのパスを「%TargetPdfFilePath%」、分割したページの出力先のパスを「%OutputFolderPath%」、検索する文字列を「%FindText%」として設定します。

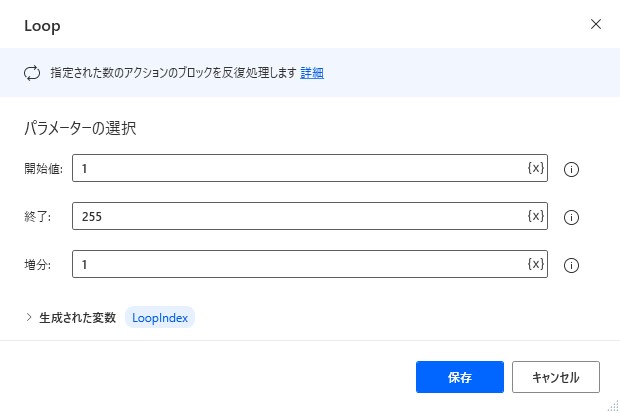
2. Loop
ループ内で「新しい PDF ファイルへの PDF ファイル ページの抽出」アクションを実行して、1ページごとに新しいPDFとして出力します。
このときループの終了値として指定したPDFのページ数を超える値を指定しておきます。
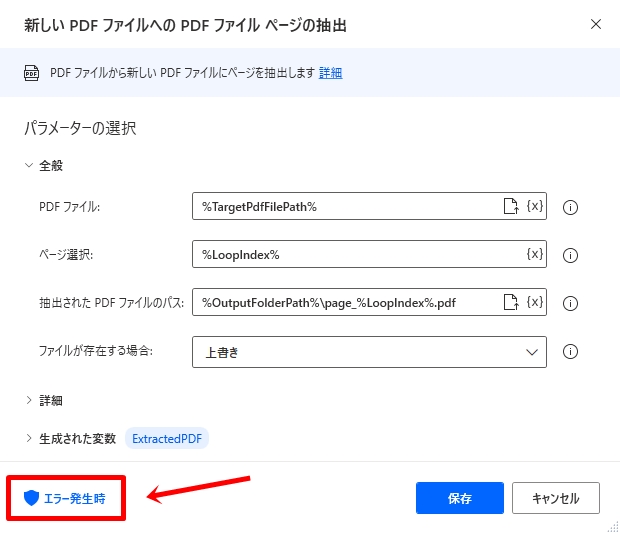
3. 新しい PDF ファイルへの PDF ファイル ページの抽出
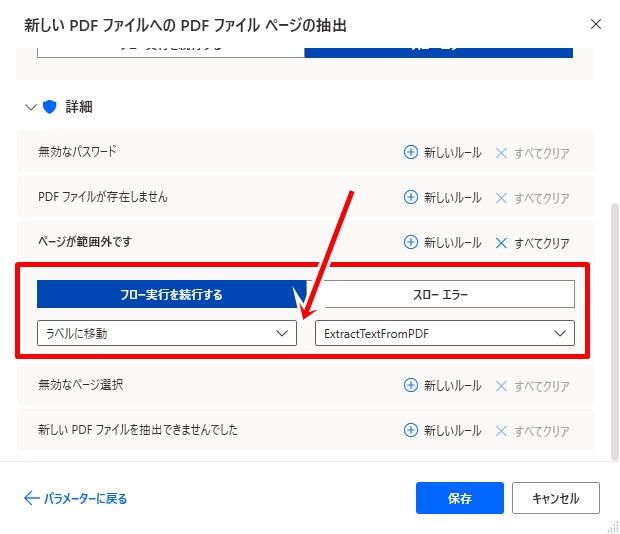
「ページが範囲外です」エラーが発生したときに指定したラベル(ExtractTextFromPDF)に移動するように設定し、ページの上限を超えたらループを抜けて処理を続行します。
・PDF ファイル:%TargetPdfFilePath%
・ページ選択:%LoopIndex%
・抽出された PDF ファイルのパス:%OutputFolderPath%\page_%LoopIndex%.pdf
・ファイルが存在する場合:上書き
4. ラベル
・名前:ExtractTextFromPDF
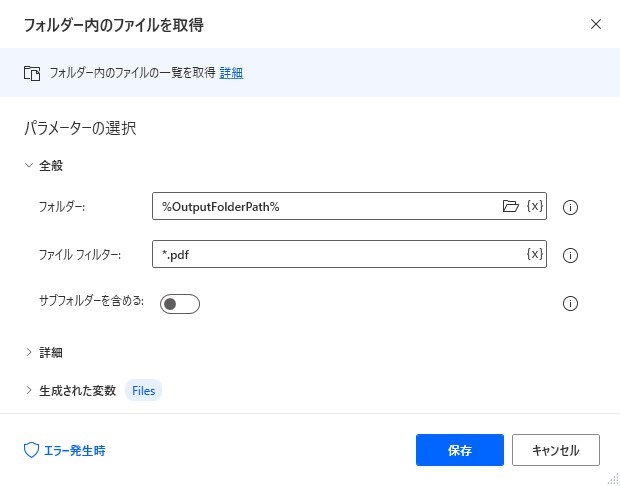
5. フォルダー内のファイルを取得
分割したPDFの出力先フォルダからファイル一覧(PDFファイルのみ)を取得します。
・フォルダー:%OutputFolderPath%
・ファイル フィルター:*.pdf
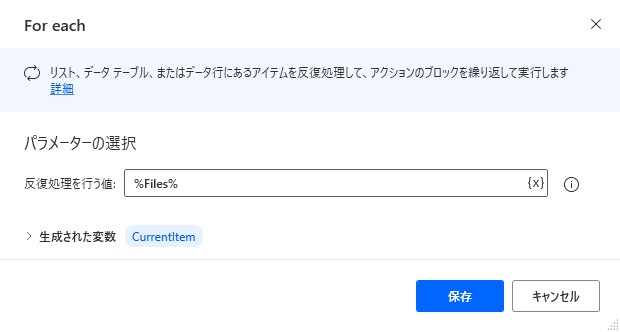
6. For each
For eachで1ファイルずつ処理します。
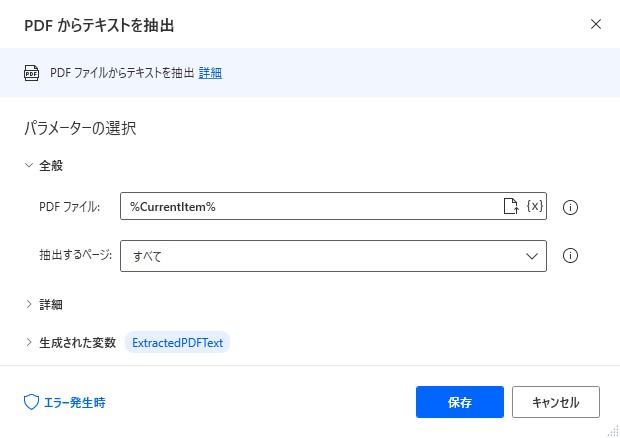
7. PDF からテキストを抽出
PDFからテキストを抽出します。
・PDF ファイル:%CurrentItem%
・抽出するページ:すべて
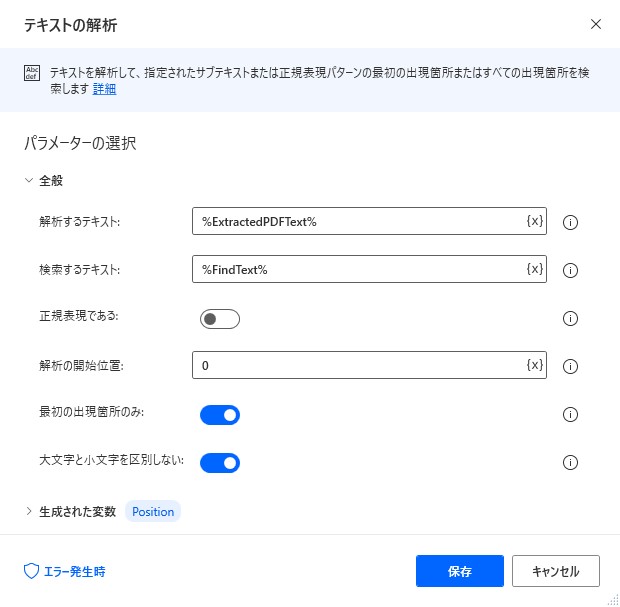
8. テキストの解析
PDF内に指定した文字列が含まれているかどうかを検索します。
検索条件は必要に応じて変更してください。
・解析するテキスト:%ExtractedPDFText%
・検索するテキスト:%FindText%
・正規表現である:オフ
・解析の開始位置:0
・最初の出現箇所飲み:オン
・大文字と小文字を区別しない:オン
・生成された変数:%Position%
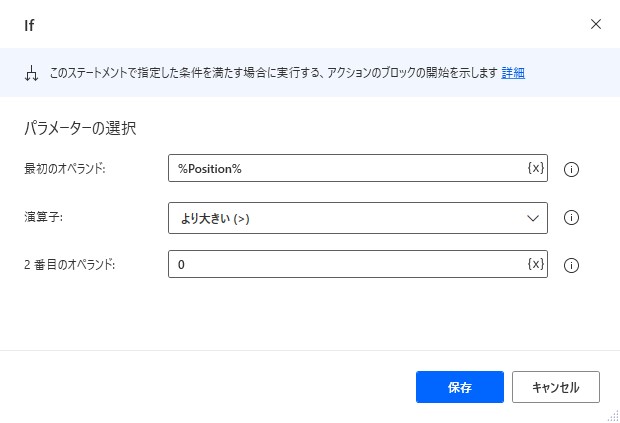
9. If
「テキストの解析」アクションで検索したテキストがヒットした場合は位置が、ヒットしなかった場合は「-1」が変数「%Position%」に格納されるので、Ifアクションを使ってヒットしたかどうかを判別します。
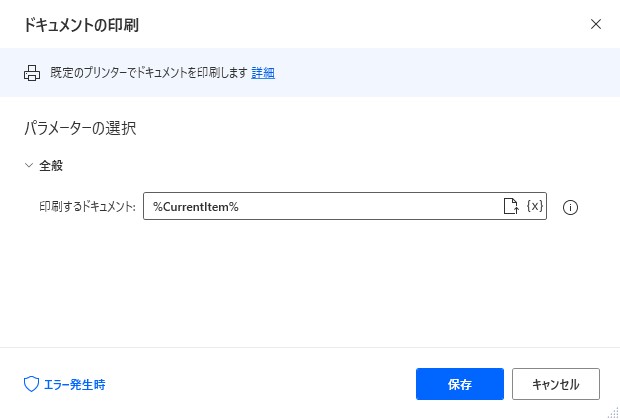
10. ドキュメントの印刷
ヒットした場合は対象となるPDFを印刷します。
「ドキュメントの印刷」アクションはファイルの右クリックメニューにある「印刷」を実行したときと同じ動きをするため、PDFを印刷する場合は既定のアプリケーションをAcrobatやAcrobat Reader等、印刷に対応したアプリケーションに設定する必要があります。
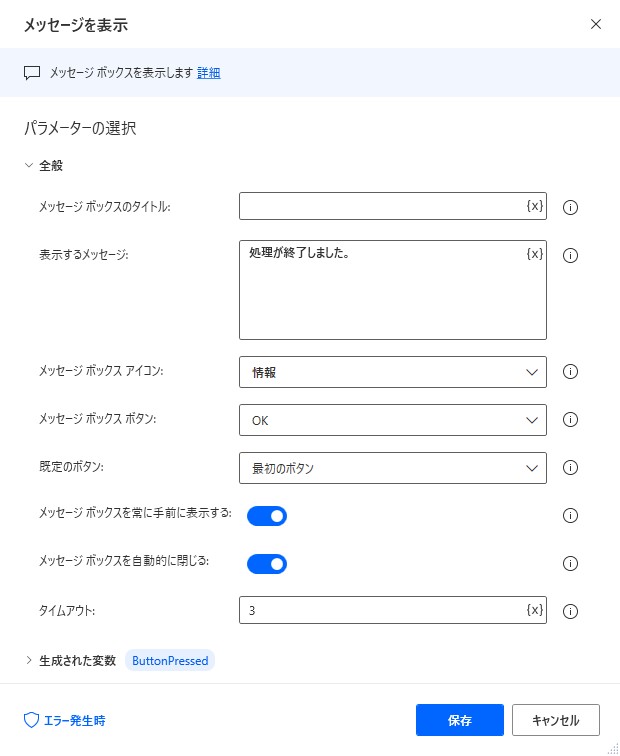
11. メッセージを表示
修了確認用のメッセージボックスを表示します。
上記の通りPDFを1ページずつ分割してテキストを抽出し、検索してヒットしたファイルのみを印刷することで、目的を達成することができました。
ただし、「PDF からテキストを抽出」アクションではテキストが埋め込まれていないPDFからはテキストを抽出できませんので、OCRにかける等の何らかの処理を行う必要があります。
“PDFで任意のキーワードが含まれているページのみを印刷するフロー”、これは面白そう!勝手に試してみましたが、↓のような流れで処理できそうです🙂 #PowerAutomateDesktop
1. 指定したPDFを1ページごとに分割
2. 1.のPDFからテキストを抽出
3. 2.のテキストを検索してヒットしたら印刷 https://t.co/gtTiFZLJCC pic.twitter.com/o6iKjiKKN9— きぬあさ (@kinuasa) August 19, 2021










この記事へのコメントはありません。